Semantic Segmentation with the Masterful CLI Trainer¶

In this guide, you will take a deeper look at Semantic Segmentation with the Masterful CLI Trainer to train a state of the art model.
This guide will use the Oxford Pets dataset, which is a small dataset of cats and dogs with included segmentation masks.
Define the Application¶
In this guide, your challenge is to build a CV model that can identify cats and dogs in an image. Importantly though, we want to classify, at a pixel level, where the animals are in the image. This is different than a standard classification task where you are only interested in the absence or presence of an animal, or a detection task where you only want a bounding box around the animal. Segmentation is an important task when the shape and outline of the object is important, such as detecting the presence of cancerous cells in a medical image. In this case, the shape of the cells is critical in determining whether or not the cells are cancerous, and providing the exact regions of interest at the pixel level can assist a medical examiner in understanding the diagnosis.
Since you want to identify each pixel in the image the CV task for this problem is semantic segmentation.
TL;DR¶
Don’t want to read the rest of this guide, and want to start training immediately? The following command shows you how to start training with Masterful, using a configuration file and dataset on S3.
masterful-train --config https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/training.yaml
Prepare the Data¶
For this guide, you will use the Oxford Pets dataset, which is a dataset of cats and dogs used for image classification, object detection, and semantic segmentation. In this section, you will take the raw dataset and convert it into a format that Masterful can understand. Along the way, you will visualize a few examples of the data to see both the input to the model, as well as the predictions after training the model.
The original dataset can be downloaded from the above link. The dataset contains two separate tar files, the images and the annotations. The following is a description of the annotations from the README file in the download:
We have created a 37 category pet dataset with roughly 200 images for each class. The images have a large variations in scale, pose and lighting. All images have an associated ground truth annotation of breed, head ROI, and pixel level trimap segmentation.
Contents:
--------
trimaps/ Trimap annotations for every image in the dataset.
Pixel Annotations: 1: Foreground 2:Background 3: Not classified
xmls/ Head bounding box annotations in PASCAL VOC Format
list.txt Combined list of all images in the dataset
Each entry in the file is of following nature:
Image CLASS-ID SPECIES BREED ID
ID: 1:37 Class ids
SPECIES: 1:Cat 2:Dog
BREED ID: 1-25:Cat 1:12:Dog
All images with 1st letter as capital are cat images
while images with small first letter are dog images.
trainval.txt Files describing splits used in the paper. However,
test.txt you are encouraged to try random splits.
The trimaps are single channel PNG images whose values are 1: Foreground 2:Background 3: Not classified. The Not classified class corresponds to a border region around the Foreground class. Since you are building a binary segmentation model, you will treat the Not classified class as Background, leaving you with only two classes - Background (not cat or dog) and Foreground (cat or dog).
The Masterful CSV format for semantic segmentation consists of only two columns - the relative path to the image and the relative path to the segmentation mask. For example, below is a snippet of the CSV file used for training in this guide:
data/Sphynx_158_train.jpeg,data/Sphynx_158_train_mask.png
data/english_cocker_spaniel_135_train.jpeg,data/english_cocker_spaniel_135_train_mask.png
data/British_Shorthair_181_train.jpeg,data/British_Shorthair_181_train_mask.png
data/Siamese_161_train.jpeg,data/Siamese_161_train_mask.png
data/Sphynx_178_train.jpeg,data/Sphynx_178_train_mask.png
.
.
.
Note that the segmentation masks are 0-indexed single channel PNGs. As part of the conversion process for this dataset, you should ensure that the two classes are labeled 0 and 1, rather than 1 and 2 as in the original trimaps. For clarity, the converted dataset below has 0 represent the Background and 1 represent Foreground.
You can read more about the semantic segmentation CSV format here.
Converting each dataset is typically a one-off operation that is different for every dataset you want to train with. For brevity, you can use the already converted dataset located at the public S3 bucket s3://masterful-public/datasets/oxford_pets_binary_segmentation/. In this bucket, you will see the following files:
oxford_pets_binary_segmentation\
test.csv
train.csv
training.yaml
label_map.csv
data\
Explore the Data¶
You should always visually inspect your dataset to get a sense of what the model will see, and to roughly verify that your dataset conversion routine worked properly and you are not training with corrupted or incorrect data. This is especially important for semantic segmentation since it is very easy to generate incorrect masks during dataset conversion.
[3]:
# Install dependencies necessary to run the following
# code.
!pip install opencv-python-headless --quiet
!pip install masterful --quiet
# Import the packages used below.
import matplotlib.pyplot as plt
import os
import requests
import tarfile
import tempfile
import tensorflow as tf
import urllib.request
# Import and activate the Masterful package.
import masterful
masterful = masterful.activate()
# Helper function to display a progress when downloading
# a file using HTTP.
from masterful.utils.downloader import progress_bar_factory
# This is necessary for running inside of Colab/Jupyter,
# since the CLI trainer is run outside of the kernel
# (as a script command).
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
MASTERFUL: Your account has been successfully activated. Masterful v0.5.2 is loaded.
[5]:
DATASET_ROOT = "https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/"
TRAINING_CSV_URL = os.path.join(DATASET_ROOT, "train.csv")
with tempfile.TemporaryDirectory() as temp_directory:
training_csv_name = os.path.join(temp_directory, "train.csv")
_ = urllib.request.urlretrieve(TRAINING_CSV_URL, training_csv_name)
examples = []
with open(training_csv_name) as training_csv:
examples = training_csv.readlines()
image1_path, mask1_path = examples[0].split(',')
image2_path, mask2_path = examples[1].split(',')
image1 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, image1_path))).read(), channels=3, dtype=tf.float32)
mask1 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, mask1_path))).read(), channels=1)
image2 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, image2_path))).read(), channels=3, dtype=tf.float32)
mask2 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, mask2_path))).read(), channels=1)
f, axarr = plt.subplots(2, 2, figsize=(15,15))
_ = axarr[0, 0].imshow(image1)
_ = axarr[0, 1].imshow(mask1)
_ = axarr[1, 0].imshow(image2)
_ = axarr[1, 1].imshow(mask2)

Configure the CLI Trainer¶
The Masterful CLI Trainer is a command line tool that trains a production quality model with no code required. The Masterful CLI Trainer take a YAML configuration file as input. The configuration file fully specifies everything necessary for training, including the dataset, model, export formats, and evaluation metrics.
Choosing a Model¶
Masterful provides many different state of the art semantic segmentation models that you can choose from. In general, choosing a model can have different constraints than training the model (are you deploying on server or edge? Runtime or latency constraints? Memory constraints?). You generally want to choose a model that is large enough to fit your data, but not so large as to overfit the training data and “memorize” the results, which can lead to poor generalization performance.
The Masterful Semantic Segmentation Model Zoo supports the following model architectures.
Model Name |
Year |
Description |
|---|---|---|
|
2015 |
U-Net with ResNet-50 V1 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with ResNet-101 V1 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with ResNet-152 V1 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B0 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B1 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B2 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B3 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B4 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B5 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B6 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with EfficientNet-B7 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with DenseNet-121 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with DenseNet-169 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with DenseNet-201 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with Inception ResNet V2 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with Inception V3 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with MobileNet backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with MobileNet V2 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with ResNeXt-50 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with ResNeXt-101 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-Net-154 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNet-18 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNet-34 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNet-50 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNet-101 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNet-152 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNeXt-50 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with SE-ResNeXt-101 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with VGG-16 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
|
2015 |
U-Net with VGG-19 backbone, from the paper U-Net: Convolutional Networks for Biomedical Image Segmentation |
The Configuration File¶
The following section is a condensed YAML configuration file for training against this dataset with NO unlabeled data. It points to the dataset created above, and selects a unet_resnet50v1 model, which is a good general model to start with on segmentation tasks. You will train at an input resolution of 320x320, so make sure to run on an instance with sufficient GPU memory to support this resolution. The input resolution for semantic segmentation has a large impact on the amount of
GPU memory required for training, so if you run into out of memory errors, try training on a larger instance or reducing the input resolution to a more manageable size.
Note all of the model artifacts will be saved to the directory ~/model_output, which you can configure in the output section below.
The original YAML file can be found here.
dataset:
root_path: 'https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation'
splits: [train, test]
label_map: label_map
optimize: True
label_format: segmentation_csv
model:
architecture: unet_resnet50v1
num_classes: 1
input_shape: [320,320,3]
training:
task: semantic_segmentation
training_split: train
output:
formats: [saved_model, onnx]
path: ~/model_output
evaluation:
split: test
Train the Model¶
Training the model involves simply running the Masterful CLI Trainer (masterful-train) against the YAML file on S3. Below, you will setup the CLI and configuration file to run in this notebook. However, if you want to train this model outside of the notebook, against the dataset on S3, you can run:
masterful-train --config https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/training.yaml
NOTE: Semantic segmentation models are quite large. Depending on your GPU, this could take several hours to complete, so plan accordingly.
[39]:
# Use the Masterful CLI to train the model without unlabeled data
!masterful-train --config https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/training.yaml
MASTERFUL: Your account has been successfully activated. Masterful v0.5.2 is loaded.
MASTERFUL [13:09:48]: Training with configuration 'https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/training.yaml':
---------- ----------------------------------------------------------------------------------------------------------
dataset root_path https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation
splits ['train', 'test']
label_map label_map
optimize True
label_format segmentation_csv
model architecture unet_resnet50v1
num_classes 1
input_shape [320, 320, 3]
training task semantic_segmentation
training_split train
output formats ['saved_model', 'onnx']
path ~/model_output
evaluation split test
---------- ----------------------------------------------------------------------------------------------------------
MASTERFUL [13:09:49]: Building model 'unet_resnet50v1'...
MASTERFUL [13:09:55]: Using model unet_resnet50v1 with:
MASTERFUL [13:09:55]: 32561114 total parameters
MASTERFUL [13:09:55]: 32513556 trainable parameters
MASTERFUL [13:09:55]: 47558 untrainable parameters
MASTERFUL [13:09:58]: Dataset Summary:
MASTERFUL [13:09:58]: Training Dataset: 3678 examples.
MASTERFUL [13:09:58]: Validation Dataset: 0 examples.
MASTERFUL [13:09:58]: Test Dataset: 3669 examples.
MASTERFUL [13:09:58]: Unlabeled Dataset: 0 examples.
MASTERFUL [13:09:58]: Training Dataset Analysis:
100%|███████████████████████████████████████| 3678/3678 [00:44<00:00, 83.56it/s]
MASTERFUL [13:10:42]: Training dataset analysis finished at 13:10:42 in 44 seconds (44s), returned:
------------------------------ ----------------------------------------
Total Examples 3678
Label Counts Background 3678
Foreground 3671
Label Distribution Background 0.500476
Foreground 0.499524
Balanced Yes
Label Distribution (Per Pixel) Background 0.708335
Foreground 0.291665
Per Channel Mean [119.670971 113.08012666 98.07536073]
Per Channel StdDev [58.93385745 58.42912248 58.57428595]
Min Height 108
Min Width 114
Max Height 2606
Max Width 3264
Average Height 383
Average Width 431
Largest Image (2448, 3264, 3)
Smallest Image (108, 144, 3)
Duplicates 0
------------------------------ ----------------------------------------
MASTERFUL [13:10:42]: Test Dataset Analysis:
100%|███████████████████████████████████████| 3669/3669 [00:45<00:00, 80.81it/s]
MASTERFUL [13:11:27]: Test dataset analysis finished at 13:11:27 in 45 seconds (45s), returned:
------------------------------ ----------------------------------------
Total Examples 3669
Label Counts Background 3669
Foreground 3662
Label Distribution Background 0.500477
Foreground 0.499523
Balanced Yes
Label Distribution (Per Pixel) Background 0.701462
Foreground 0.298538
Per Channel Mean [121.5643097 115.65385582 98.55302601]
Per Channel StdDev [59.33446071 58.66978229 59.12515804]
Min Height 103
Min Width 137
Max Height 2160
Max Width 1646
Average Height 399
Average Width 443
Largest Image (2160, 1440, 3)
Smallest Image (103, 137, 3)
Duplicates 0
------------------------------ ----------------------------------------
MASTERFUL [13:11:27]: Cross-Dataset Analysis:
MASTERFUL [13:11:27]: Cross-Dataset analysis finished at 13:11:27 in 0 seconds (0s), returned:
----- --------
train train 0
test 0
test train 0
test 0
----- --------
MASTERFUL [13:11:28]: Meta-Learning architecture parameters...
MASTERFUL [13:11:28]: Architecture learner finished at 13:11:28 in 1 seconds (1s), returned:
------------------------------ -----------------------------
task Task.SEMANTIC_SEGMENTATION
num_classes 1
ensemble_multiplier 1
custom_objects {}
model_config
backbone_only False
input_shape (None, None, 3)
input_range ImageRange.ZERO_255
input_dtype <dtype: 'float32'>
input_channels_last True
prediction_logits True
prediction_dtype <dtype: 'float32'>
prediction_structure TensorStructure.SINGLE_TENSOR
prediction_shape (None, None, 1)
total_parameters 32561114
total_trainable_parameters 32513556
total_non_trainable_parameters 47558
------------------------------ -----------------------------
MASTERFUL [13:11:28]: Meta-learning training dataset parameters...
MASTERFUL [13:11:29]: Training dataset learner finished at 13:11:29 in 1 seconds (1s), returned:
------------------------- -----------------------------
num_classes 1
task Task.SEMANTIC_SEGMENTATION
image_shape (320, 320, 3)
image_range ImageRange.ZERO_255
image_dtype <dtype: 'float32'>
image_channels_last True
label_dtype <dtype: 'float32'>
label_shape (320, 320, 1)
label_structure TensorStructure.SINGLE_TENSOR
label_sparse False
label_bounding_box_format
------------------------- -----------------------------
MASTERFUL [13:11:29]: Meta-learning test dataset parameters...
MASTERFUL [13:11:30]: Test dataset learner finished at 13:11:30 in 1 seconds (1s), returned:
------------------------- -----------------------------
num_classes 1
task Task.SEMANTIC_SEGMENTATION
image_shape (320, 320, 3)
image_range ImageRange.ZERO_255
image_dtype <dtype: 'float32'>
image_channels_last True
label_dtype <dtype: 'float32'>
label_shape (320, 320, 1)
label_structure TensorStructure.SINGLE_TENSOR
label_sparse False
label_bounding_box_format
------------------------- -----------------------------
MASTERFUL [13:11:30]: Meta-Learning optimization parameters...
Callbacks: 100%|███████████████████████████████| 8/8 [02:43<00:00, 20.46s/steps]
MASTERFUL [13:14:14]: Optimization learner finished at 13:14:14 in 164 seconds (2m 44s), returned:
----------------------- -----------------------------------------------------------------
batch_size 16
drop_remainder False
epochs 1000000
learning_rate 0.0008838834473863244
learning_rate_schedule
learning_rate_callback <keras.callbacks.ReduceLROnPlateau object at 0x7feaf129e978>
warmup_learning_rate 1e-06
warmup_epochs 5
optimizer <tensorflow_addons.optimizers.lamb.LAMB object at 0x7feaf129ec18>
loss <keras.losses.BinaryCrossentropy object at 0x7fea4ccc4208>
loss_weights
early_stopping_callback <keras.callbacks.EarlyStopping object at 0x7fea2c4c5550>
metrics [<keras.metrics.BinaryAccuracy object at 0x7fea2c4c54e0>]
readonly_callbacks
----------------------- -----------------------------------------------------------------
MASTERFUL [13:14:18]: Meta-Learning Regularization Parameters...
MASTERFUL [13:14:26]: Warming up model for analysis.
MASTERFUL [13:14:29]: Warming up batch norm statistics (this could take a few minutes).
MASTERFUL [13:14:34]: Warming up training for 1035 steps.
100%|████████████████████████████████████| 1035/1035 [04:44<00:00, 3.63steps/s]
MASTERFUL [13:19:19]: Validating batch norm statistics after warmup for stability (this could take a few minutes).
MASTERFUL [13:21:54]: Analyzing baseline model performance. Training until validation loss stabilizes...
Baseline Training: 100%|█████████████████| 6440/6440 [22:15<00:00, 4.82steps/s]
MASTERFUL [13:45:07]: Baseline training complete.
MASTERFUL [13:45:07]: Meta-Learning Basic Data Augmentations...
Node 1/4: 100%|██████████████████████████| 4600/4600 [15:43<00:00, 4.88steps/s]
Node 2/4: 100%|██████████████████████████| 4600/4600 [15:50<00:00, 4.84steps/s]
Node 3/4: 100%|██████████████████████████| 4600/4600 [15:48<00:00, 4.85steps/s]
Node 4/4: 100%|██████████████████████████| 4600/4600 [15:47<00:00, 4.86steps/s]
MASTERFUL [14:52:02]: Meta-Learning Data Augmentation Clusters...
Distance Analysis: 100%|███████████████████| 143/143 [04:38<00:00, 1.95s/steps]
Node 1/10: 100%|█████████████████████████| 4600/4600 [18:30<00:00, 4.14steps/s]
Node 2/10: 100%|█████████████████████████| 4600/4600 [18:29<00:00, 4.14steps/s]
Node 3/10: 100%|█████████████████████████| 4600/4600 [18:30<00:00, 4.14steps/s]
Node 4/10: 100%|█████████████████████████| 4600/4600 [18:29<00:00, 4.14steps/s]
Node 5/10: 100%|█████████████████████████| 4600/4600 [18:29<00:00, 4.15steps/s]
Distance Analysis: 100%|█████████████████████| 66/66 [02:09<00:00, 1.97s/steps]
Node 6/10: 100%|█████████████████████████| 4600/4600 [18:47<00:00, 4.08steps/s]
Node 7/10: 100%|█████████████████████████| 4600/4600 [18:46<00:00, 4.08steps/s]
Node 8/10: 100%|█████████████████████████| 4600/4600 [18:45<00:00, 4.09steps/s]
Node 9/10: 100%|█████████████████████████| 4600/4600 [18:45<00:00, 4.09steps/s]
Node 10/10: 100%|████████████████████████| 4600/4600 [18:46<00:00, 4.08steps/s]
MASTERFUL [18:15:51]: Meta-Learning Label Based Regularization...
Node 1/2: 100%|██████████████████████████| 4600/4600 [18:59<00:00, 4.04steps/s]
Node 2/2: 100%|██████████████████████████| 4600/4600 [18:59<00:00, 4.04steps/s]
MASTERFUL [18:56:01]: Meta-Learning Weight Based Regularization...
MASTERFUL [18:56:02]: Analysis finished in 341.594660727183 minutes.
MASTERFUL [18:56:02]: Learned parameters sky-alert-snow saved at /home/sam/.masterful/policies/sky-alert-snow.
MASTERFUL [18:56:02]: Regularization learner finished at 18:56:02 in 20507 seconds (5h 41m 47s), returned:
------------------------- -----------------------------------------------
shuffle_buffer_size 3311
mirror 1.0
rot90 1.0
rotate 0
mixup 0.0
cutmix 0.0
label_smoothing 0
hsv_cluster 2
hsv_cluster_to_index [[ 1 3 7 11 11 11]
[ 3 4 7 11 11 11]
[ 1 1 2 4 6 11]
[ 1 3 4 6 9 11]
[ 2 2 2 4 11 11]]
hsv_magnitude_table [[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[100 0 90 10 50 40 60 20 80 30 70]]
contrast_cluster 2
contrast_cluster_to_index [[ 3 11 11 11 11 11]
[ 1 1 1 1 1 11]
[ 2 5 5 6 6 11]
[ 2 2 3 6 11 11]
[ 1 2 4 7 11 11]
[ 1 2 4 6 9 11]]
contrast_magnitude_table [[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 100 50 20 40 30 60 90 70 80]
[ 10 0 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]]
blur_cluster 2
blur_cluster_to_index [[ 5 8 11 11 11 11]
[ 1 4 11 11 11 11]]
blur_magnitude_table [[ 0 40 10 50 30 20 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]]
spatial_cluster 3
spatial_cluster_to_index [[ 2 4 6 7 8 11]
[ 3 5 6 7 8 11]
[ 2 4 5 7 11 11]
[ 2 4 5 7 10 11]
[ 1 2 4 5 7 11]
[ 1 3 7 11 11 11]]
spatial_magnitude_table [[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 100 10 90 80 20 30 50 70 60 40]
[ 0 100 10 90 20 80 60 50 30 40 70]
[ 0 10 20 30 40 50 60 70 80 90 100]
[ 0 10 20 30 40 50 60 70 80 90 100]]
synthetic_proportion [0.0]
------------------------- -----------------------------------------------
MASTERFUL [18:56:02]: Learning SSL parameters...
MASTERFUL [18:56:03]: SSL learner finished at 18:56:03 in 1 seconds (1s), returned:
---------- --
algorithms []
---------- --
MASTERFUL [18:56:03]: Training model with semi-supervised learning disabled.
MASTERFUL [18:56:05]: Performing basic dataset analysis.
MASTERFUL [18:56:16]: Masterful will use 367 labeled examples as a validation set since no validation data was provided.
MASTERFUL [18:56:16]: Training model with:
MASTERFUL [18:56:16]: 3311 labeled examples.
MASTERFUL [18:56:16]: 367 validation examples.
MASTERFUL [18:56:16]: 0 synthetic examples.
MASTERFUL [18:56:16]: 0 unlabeled examples.
MASTERFUL [18:56:16]: Training model with learned parameters sky-alert-snow in two phases.
MASTERFUL [18:56:16]: The first phase is supervised training with the learned parameters.
MASTERFUL [18:56:16]: The second phase is semi-supervised training to boost performance.
MASTERFUL [18:56:17]: Warming up model for supervised training.
MASTERFUL [18:56:20]: Warming up batch norm statistics (this could take a few minutes).
MASTERFUL [18:56:25]: Warming up training for 1035 steps.
100%|████████████████████████████████████| 1035/1035 [05:58<00:00, 2.89steps/s]
MASTERFUL [19:02:24]: Validating batch norm statistics after warmup for stability (this could take a few minutes).
MASTERFUL [19:05:01]: Starting Phase 1: Supervised training until the validation loss stabilizes...
Supervised Training: 100%|█████████████| 11500/11500 [55:07<00:00, 3.48steps/s]
MASTERFUL [20:01:23]: Semi-Supervised training disabled in parameters.
MASTERFUL [20:01:25]: Training complete in 65.13731401761373 minutes.
MASTERFUL [20:01:29]: Saving model output to /home/sam/model_output/session-00343.
MASTERFUL [20:01:33]: Saving saved_model output to /home/sam/model_output/session-00343/saved_model
MASTERFUL [20:01:51]: Saving onnx output to /home/sam/model_output/session-00343/onnx
MASTERFUL [20:02:29]: Saving regularization params to /home/sam/model_output/session-00343/regularization.params.
MASTERFUL [20:02:29]: ************************************
MASTERFUL [20:02:29]: Evaluating model on 3669 examples from the 'test' dataset split:
Evaluating: 100%|██████████████████████████| 3669/3669 [00:13<00:00, 273.79it/s]
MASTERFUL [20:02:43]: Loss: 0.0677
MASTERFUL [20:02:43]: Binary Accuracy: 0.9740
IoU: 100%|████████████████████████████████████| 230/230 [00:23<00:00, 9.59it/s]
MASTERFUL [20:03:07]: Average Intersection over Union: 0.9298
MASTERFUL [20:03:07]:
MASTERFUL [20:03:07]: Per-Class Metrics:
MASTERFUL [20:03:07]: Class Background:
MASTERFUL [20:03:07]: Intersection over Union: 0.9678
MASTERFUL [20:03:07]: Class Foreground:
MASTERFUL [20:03:07]: Intersection over Union: 0.8918
MASTERFUL [20:03:07]: Saving evaluation metrics to /home/sam/model_output/session-00343/evaluation_metrics.csv.
MASTERFUL [20:03:07]: Total elapsed training time: 413 minutes (6h 53m 18s).
MASTERFUL [20:03:07]: Launch masterful-gui to visualize the training results: policy name 'sky-alert-snow'
Analyze the Results¶
At the end of training, Masterful will evaluate your model based on the test (sometimes called holdout) dataset you specified in the evaluation section of your configuration file. The evaluation results are different for each task, since every computer vision task has both general metrics (such as loss) as well as task-specific metrics (IoU for semantic segmentation for example). These results are printed to the console, as well as saved into a CSV file in the output directory specified in
your configuration file.
Semantic Segmentation Evaluation Metrics¶
For Semantic Segmentation, Masterful reports two main categories of metrics: Model Loss and Intersection over Union.
Model Loss¶
The first set of metrics Masterful reports is the overall loss of the model. For semantic segmentation models, Masterful reports the total loss as well as any sub-losses that are specific to the model architecture. Different models have different sub-losses, and you can gauge how your model is doing on the different tasks based on the final results of these sub-metrics.
The following is the loss results from the above training run (this might be different if you rerun the above cells):
MASTERFUL [20:02:29]: Evaluating model on 3669 examples from the 'test' dataset split:
Evaluating: 100%|██████████████████████████| 3669/3669 [00:13<00:00, 273.79it/s]
MASTERFUL [20:02:43]: Loss: 0.0677
MASTERFUL [20:02:43]: Binary Accuracy: 0.9740
As you can see in the above output, the total loss of the model is MASTERFUL [20:02:43]: Loss: 0.0677. Masterful also reports the per-pixel accuracy of the mask prediction MASTERFUL [20:02:43]: Binary Accuracy: 0.9740. An accuracy of 97.4% seems really good! However, with semantic segmentation you need to be careful when looking at overall accuracy, since its is a heavily imbalanced task. For example, let’s say your image contains 100 pixels, and only 5 of those pixels represent the
foreground object to predict. A model that predicted all background pixels would be 95% accurate, even though it never makes a correct prediction for the pixels you care about. Therefore, it’s really difficult to understand intuitively what this means in terms of your models overall performance. Are these good values? Or bad ones? Let’s dive into the rest of the metrics to answer these questions.
Quick Aside: It is possible to use the accuracy results to quantify the performance of your model, but first you must understand the per-pixel distribution of classes in the evaluation data. For example, if the distribution of classes is roughly balanced on a pixel level, then the accuracy indicator will be a good indicator of the predictive performance of your model. But how do we know the per-pixel label distribution of our training and evaluation data? Masterful will tell you this in the
dataset analysis section. Below is the snippet from the Test Dataset Analysis performed at the start of training:
Label Distribution (Per Pixel) Background 0.701462
Foreground 0.298538
In this example, a biased model that predicted all background would be correct only 70% of the time, and an unbiased random model would be correct 50% of the time. So based on a binary accuracy of 97.4%, it is safe to assume your model has both not collapsed to a single prediction and is doing better than random. So it is likely that your model is performing well. So next you will take a closer look and verify those results.
Intersection over Union¶
Intersection over Union is a measure of overlap between two regions. Formally, it is defined as:
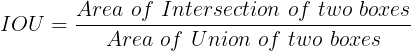
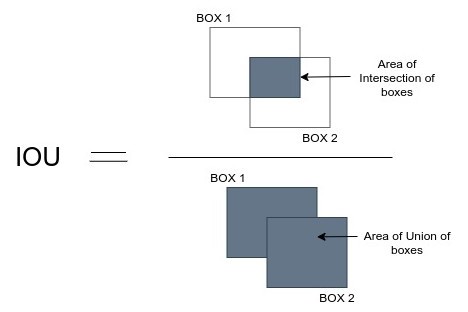
Intesection over Union is a helpful metric because it can tell you how close the predicted masks match the groundtruth data. For example, in the 100 pixel example above, if the model predicted all background class, the IoU on the foreground class would be 0, because there would be no overlap between the predicted mask and the groundtruth data.
Below is the average IoU and the per-class IoU metrics for the training run above:
IoU: 100%|████████████████████████████████████| 230/230 [00:23<00:00, 9.59it/s]
MASTERFUL [20:03:07]: Average Intersection over Union: 0.9298
MASTERFUL [20:03:07]:
MASTERFUL [20:03:07]: Per-Class Metrics:
MASTERFUL [20:03:07]: Class Background:
MASTERFUL [20:03:07]: Intersection over Union: 0.9678
MASTERFUL [20:03:07]: Class Foreground:
MASTERFUL [20:03:07]: Intersection over Union: 0.8918
As you can see from both the average IoU (Average Intersection over Union: 0.9298) and the per-class IoU, the model is performing pretty well on predicting the segmentation masks.
View the Predictions¶
While the IoU metrics are a good quantitative indicator of the performance of your model, visualizing the predictions can help you get a qualititative sense of how well your trained model is performing. Below you can see the predictions for the above trained model on the examples you visualized above.
[10]:
import numpy as np
# Download the pretrained model so that you can
# visualize the results.
MODEL_URL = "https://masterful-public.s3.us-west-1.amazonaws.com/datasets/oxford_pets_binary_segmentation/trained_model.tar.gz"
model = None
with tempfile.TemporaryDirectory() as temp_directory:
# Download the pretrained model from S3.
saved_model_path = os.path.join(temp_directory, "saved_model.tar.gz")
_ = urllib.request.urlretrieve(MODEL_URL, saved_model_path, progress_bar_factory("Downloading Model: "))
# Extract the model weights from the tar file.
with tarfile.open(saved_model_path) as tar:
tar.extractall(temp_directory)
saved_model_path = os.path.join(temp_directory, "saved_model")
# Load the trained tensorflow saved model.
model = tf.saved_model.load(saved_model_path)
image1_path, mask1_path = examples[0].split(',')
image2_path, mask2_path = examples[1].split(',')
image1 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, image1_path))).read(), channels=3, dtype=tf.uint8)
mask1 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, mask1_path))).read(), channels=1)
image2 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, image2_path))).read(), channels=3, dtype=tf.uint8)
mask2 = tf.io.decode_image(urllib.request.urlopen(urllib.request.Request(os.path.join(DATASET_ROOT, mask2_path))).read(), channels=1)
# The default inference function for tensorflow saved
# models is named `serving_default`.
inference_fn = model.signatures["serving_default"]
# The inference function is a one-arg callable, whose
# input argument is `image` - the image to predict on,
# and which returns a dictionary of outputs. The dictionary
# contains an item whose key is `prediction`, which is the
# predictions of the model.
image1_predictions = inference_fn(image=image1)['prediction']
image2_predictions = inference_fn(image=image2)['prediction']
# Threshold the predictions to determine the class prediction
image1_predictions = np.where(image1_predictions.numpy() >= 0.5, np.ones_like(image1_predictions), np.zeros_like(image1_predictions))
image2_predictions = np.where(image2_predictions.numpy() >= 0.5, np.ones_like(image2_predictions), np.zeros_like(image2_predictions))
# Plot a few different instances from the dataset.
f, axarr = plt.subplots(2, 3, figsize=(15,15))
_ = axarr[0, 0].imshow(image1)
_ = axarr[0, 1].imshow(mask1)
_ = axarr[0, 2].imshow(image1_predictions)
_ = axarr[1, 0].imshow(image2)
_ = axarr[1, 1].imshow(mask2)
_ = axarr[1, 2].imshow(image2_predictions)
f.tight_layout()
Downloading Model: 100% (121342367 of 121342367) || Elapsed Time: 0:00:13 Time: 0:00:13

As you can see above, the predicted masks are quite accurate and represent a well-trained model.
Using the Model for Inference¶
The Output Formats guide has more information about how to use the models output by Masterful. Semantic Segmentation has a few other intricacies that should be addressed though, since the model outputs a prediction for every pixel in the input image. Above, you used the trained model to generate predictions, and view the predictions side by side with the ground truth label. The predictions are floating point values in the range [0, 1], so
it’s important to convert these into discrete class predictions. Since this is a binary prediction task, you can do this with a basic threshold. Below you can see the snippets from above that handled making predictions and thresholding those predictions for accurate per-pixel class predictions.
# Load the trained tensorflow saved model.
model = tf.saved_model.load(saved_model_path)
# The default inference function for tensorflow saved
# models is named `serving_default`.
inference_fn = model.signatures["serving_default"]
# The inference function is a one-arg callable, whose
# input argument is `image` - the image to predict on,
# and which returns a dictionary of outputs. The dictionary
# contains an item whose key is `prediction`, which is the
# predictions of the model.
image1_predictions = inference_fn(image=image1)['prediction']
image2_predictions = inference_fn(image=image2)['prediction']
# Threshold the predictions to determine the class prediction
image1_predictions = np.where(image1_predictions.numpy() >= 0.5,
np.ones_like(image1_predictions),
np.zeros_like(image1_predictions))
image2_predictions = np.where(image2_predictions.numpy() >= 0.5,
np.ones_like(image2_predictions),
np.zeros_like(image2_predictions))
Next Steps¶
In the above sections, you have learned how to train a semantic segmentation model using the Masterful CLI, evaluate the performance of the model, and use the model to make predictions on your production data.
If you want to look at other use cases, you will find an Object Detection guide as well a more advanced Object Detection example, Detecting Pedestrians in Street Level Imagery. Otherwise, feel free to explore Classifying Land Use for other examples of using the Masterful CLI Trainer to solve challenging computer vision problems.