Introduction to Semi-Supervised Learning¶
Title: Introduction to Semi-Supervised Learning
Author: sam
Date created: 2022/03/29
Last modified: 2022/03/29
Description: Introduction to Semi-Supervised Learning.
Introduction¶
In a previous blog post, we showed that throwing more training data at a deep learning model has rapidly diminishing returns. If doubling your labeling budget won’t move the needle, what next? Consider semi-supervised learning (SSL) to unlock the information in unlabeled data. This guide introduces the definition, concepts, and recent techniques used in semi-supervised learning, and how to take advantage of them in the Masterful platform.
What is Semi-Supervised Learning¶
Semi-supervised learning (SSL) is a machine learning approach that combines labeled and unlabeled data during training. Semi-supervised learning traditionally falls between unsupervised learning (no labeled training data) and supervised learning (no unlabeled training data). However, one can also look at semi-supervised learning as the superset of techniques, where unsupervised learning represents semi-supervised learning with no labeled training data, and supervised learning is semi-supervised learning with no unlabeled training data.
Types of Semi-Supervised Learning¶
SSL has a long history of classical techniques. Self training, a form of SSL which uses a teacher model to train a student model, was introduced back in the ’60s for example. More recently, deep semi-supervised learning methods have been introduced that can exploit the inductive frameworks of modern deep learning. In this guide, we will focus on these deep semi-supervised learning approaches, since they are the focus of most recent research and are the techniques implemented inside Masterful.
Consistency Regularization Methods¶
Consistency regularization methods apply a consistency regularization term to the final loss function, which prior constraints on the loss modeled by the researcher. For example, this could be an augmentation constraint, such that realistic perturbations of the training data should not change the output of the model. Unsupervised Data Augmentation and Barlow Twins are two popular consistency based regularization approaches. Consistency based approaches are a form of self-supervision, where training learns the supervisory signals from the data itself, as modeled by the consistency constraints imposed by the researcher.
Pseudo-Labeling Methods¶
Pseudo-labeling methods rely on the high confidence of pseudo-labels which can be added to the training dataset as labeled data. This is in contrast to consistency based regularization methods which rely on a consistency contstraint of rich data transformations. Pseudo-labeling methods generally fall into two main patterns. The first is disagreement based methods, where two models are jointly trained to exploit the disagreement amongst the separate views. The second is self-training, which uses a teacher-student pattern to leverage the models own confident predictions to produce the pseudo-labels for the unlabeled data. Noisy Student and SimCLR v2 are two popular pseudo-labeling methods.
Graph-based Methods¶
Graph-based semi-supervised learning is a method of techniques which extract a graph representation from the raw dataset, where each node represents a training sample and each edge represents some similarity between the node pairs. The principal goal is to encode the labeled dataset as a graph such that the label information for unlabeled examples can be inferred from the graph representation. There is a good survey of graph-based semi-supervised learning here.
Generative Methods¶
Generative methods are semi-supervised learning methods that learn the implicit features of the data distribution. These include recent work such as Generative Adversarial Networks and Variational Auto-Encoders. These are typically excellent methods to generate additional training examples, as a form of semi-supervised synthetic data.
Hybrid Methods¶
Hybrid methods are any method that combines idea from the previously mentioned methods, such as pseudo-labeling and consistency regularization. FixMatch, MixMatch, and ReMixMatch are a popular family of hybrid semi-supervised learning methods.
For a good survey of deep semi-supervised learning, and which introduces the taxonomy above, see A Survey on Deep Semi-Supervised Learning.
How Can Semi-Supervised Learning Help Me?¶
SSL means learning from both labeled and unlabeled data. But first, make sure you are getting the most out of your labeled data. Try a bigger model architecture and tune your regularization hyperparameters. (or let the Masterful platform handle this for you). Once you have a big enough model architecture and optimal regularization hyperparameters, the limiting factor is now information. An even bigger, more regularized model won’t deliver better results until you train with more information .
But wait - it seems like we are stuck between a rock and a hard place. There’s no more labeling budget and yet the model needs information. How do we resolve this? The key insight: labeling is not your only source of information… unlabeled data also has information! Semi-supervised learning is the key to unlocking the information in unlabeled data.
SSL is great because there is usually a lot more unlabeled data than labeled, especially once you deploy into production. Avoiding labeling also means avoids the time, cost, and effort of labeling.
Practically, what does this mean for me? In the Using Unlabeled Data Part 1 and Using Unlabeled Data Part 2 we show that you can train a model to production quality (over 75% accuracy) using semi-supervised learning with only 50 labeled examples per class. The same model, trained only on the labeled training examples, barely performs better than random. This is a dramatic improvement in your model with no additional labeled training data!
But if there are no labels, am I getting “something for nothing”?¶
Absolutely not. As we mentioned above, unlabeled data has a ton of information that can be used during training. It all depends on how we take advantage of that information. For example, many SSL techniques rely on a low-density separation assumption. This means the decision boundary for classes should reside in a low-density region of some embedding space. Therefore, we can use this assumption to find an embedding space that generates nicely separable high and low density regions or clusters. Self-supervised techniques, such as SWaV are able to generate these embeddings simply from the features of the data itself, such as comparing contrasting views of an image and enforcing the constraint that each view generates an embedding in the same cluster.
So in essence, the additional information for semi-supervised learning comes from the unlabeled data itself, guided by meta-knowledge from you the developer. The meta-knowledge takes the form of your understanding of the data (low-density separation, co-training assumption, clustering assumption, generative distribution assumption, maniold similarity assumption, etc) as well as semantic assumptions (two views of the same image equate to the same label). The beauty of semi-supervised learning is that it formalizes a way to transfer human meta-knowledge and unlabeled data into a machine learning model.
Semi-Supervised Learning in Masterful¶
The Masterful platform for training CV models offers three ways to train with SSL.
First, in the full platform, the masterful.training.train function implements an SSL technique that allows you to run both supervised training and improve your model using unlabeled data in a single training function. Our CIFAR-10 benchmark report shows a reduction in error rate from 0.28 to 0.22 using unlabeled data.
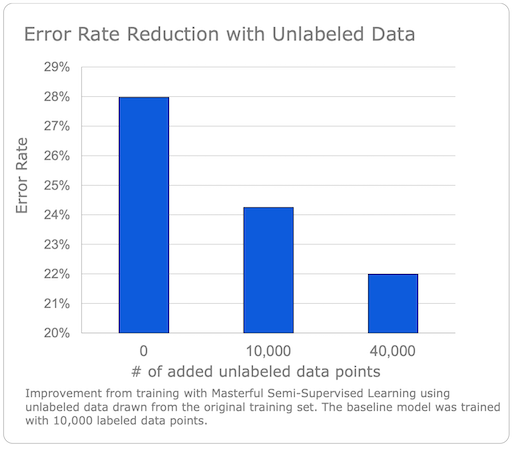
You can learn more about this process in Using Unlabeled Data Part 1.
Second, we include a function, masterful.ssl.learn_representation, to help you pretrain a feature extractor. Once your feature extractor is trained, attach your classification / segmentation / detection head and fine tune using the Masterful training loop with built-in fine-tuning, or, use your own fine-tuning setup. By starting with these weights instead of pseudo-randomly initialized weights, you can get a better final accuracy, especially in low-shot scenarios. You can learn more about this process in Using Unlabeled Data Part 2
Finally, we have a recipe that lets you train with your existing training loop and regularization scheme. This is a quick way to get started with SSL. Use the helper function masterful.ssl.analyze_data_then_save_to to analyze your datasets and save the analysis to disk. Then masterful.ssl.load_from to return a tf.data.Dataset object you can pass to your training loop. Check out the guide here.